

There is a lot of serious work happening right now on AI audit and assurance. The UK government has published its Trusted Third-Party AI Assurance Roadmap and is funding pilots through DSIT. Singapore’s AI Verify Foundation has been operational for several years and continues to evolve. The Partnership on AI runs a dedicated Strengthening the AI Assurance Ecosystem workstream. The Ada Lovelace Institute is pressing on who the professional AI assurance community is actually supposed to be, and the International Association of Algorithmic Auditors (IAAA) has been answering. ForHumanity continues to develop audit schemes for compliance with a number of AI regulations. US state legislatures, most recently Virginia, are researching what it would take for an Independent Verification Organization (IVO) to operate credibly. Academic work on testing and auditing of AI systems is active and growing. I spend a lot of time in these conversations, and I admire a lot of what is being produced.
Two observations about that conversation before I make my actual argument. First, what most of these efforts are really asking about is not management system auditing, the “do you have a governance process in place” exercise that ISO/IEC 42001 is designed for. Those have their place and are incredibly valuable.
What the conversation is really about is technical, system-level assurance: independent attestation that a particular AI system, in a particular deployment context, actually behaves the way someone claims it does.
That it is reasonably safe, secure, fair, accurate, and governed in the ways the deployer says it is. Second, it is not exclusively about TEVV either, though some of it is. Testing, evaluation, verification, and validation (TEVV) is what gets done to the system, and I’ve written elsewhere about how we approach the TEVV side in practice. Assurance is the distinct layer above TEVV, where an independent practitioner applies professional judgment to the evidence TEVV produces and issues an opinion that someone else can reasonably rely on (this is not always true, but more about direct vs attestation engagements later).
I want to make a point about that assurance layer specifically, because it is where I start to get nervous. What worries me is when efforts begin to redefine the profession of assurance itself, things like how independence should be structured or what makes an assurance report credible. There is already a profession that has been answering those questions for decades, with a mature international standards infrastructure behind it. In particular, ISAE 3000, the International Auditing and Assurance Standards Board’s standard for assurance engagements on subject matters other than historical financial information, is the instrument that already addresses much of what the AI field keeps trying to re-derive (Note: I could just as well be discussing the AICPA’s substantively equivalent US attestation standards). The genuine hard work is elsewhere, in the content of what we assess AI systems against and some of the nuances of how, and I’ll come back to that. Many of us are in the thick of it, and it deserves the field’s attention. But the professional scaffolding around how independent assurance is delivered does not need to be rebuilt. It needs to be read in the context of this new object of evaluation.
Why Financial Auditing is an Okay Analogy
When people resist the financial auditing analogy, the objection is usually something like: “AI systems are dynamic and complex in ways that balance sheets aren’t.” That’s true as far as it goes. But the deeper logic of what a financial audit actually does has nothing to do with the specific content being audited. It has to do with the relationship between a claim, evidence, and an independent opinion.
When a company publishes audited financial statements, what the audit provides is not certainty. It provides a structured, evidence-based opinion from an independent professional who has applied agreed-upon criteria against the available evidence. The audit is credible because the professional is accountable to ethical standards, independence requirements, and a methodology that is visible and challengeable.
This is exactly what AI accountability at the technical system level is missing right now. The field is full of claims: vendors describing their systems as “fair,” “transparent,” or “safe,” with no consistent mechanism for an independent party to evaluate those claims against evidence and issue a defensible opinion. We have a credibility gap, and it is a governance gap. Professional assurance standards exist precisely to close this kind of gap. They’re not a perfect match, however, and they’re not sufficient without more work, but they’re a good base to work from.
What ISAE 3000 Actually Is
ISAE 3000 (Revised) is the International Auditing and Assurance Standards Board’s standard for assurance engagements on subject matters other than historical financial information. That phrasing, “other than historical financial information,” is important. It is the standard designed for situations where the thing being examined does not fit neatly into traditional financial audit territory. AI systems qualify almost by definition.
The standard establishes the core structure of any legitimate assurance engagement, and it is worth understanding this structure precisely because it has more moving parts than most people assume (Figure 1: adapted from ISAE 3000).
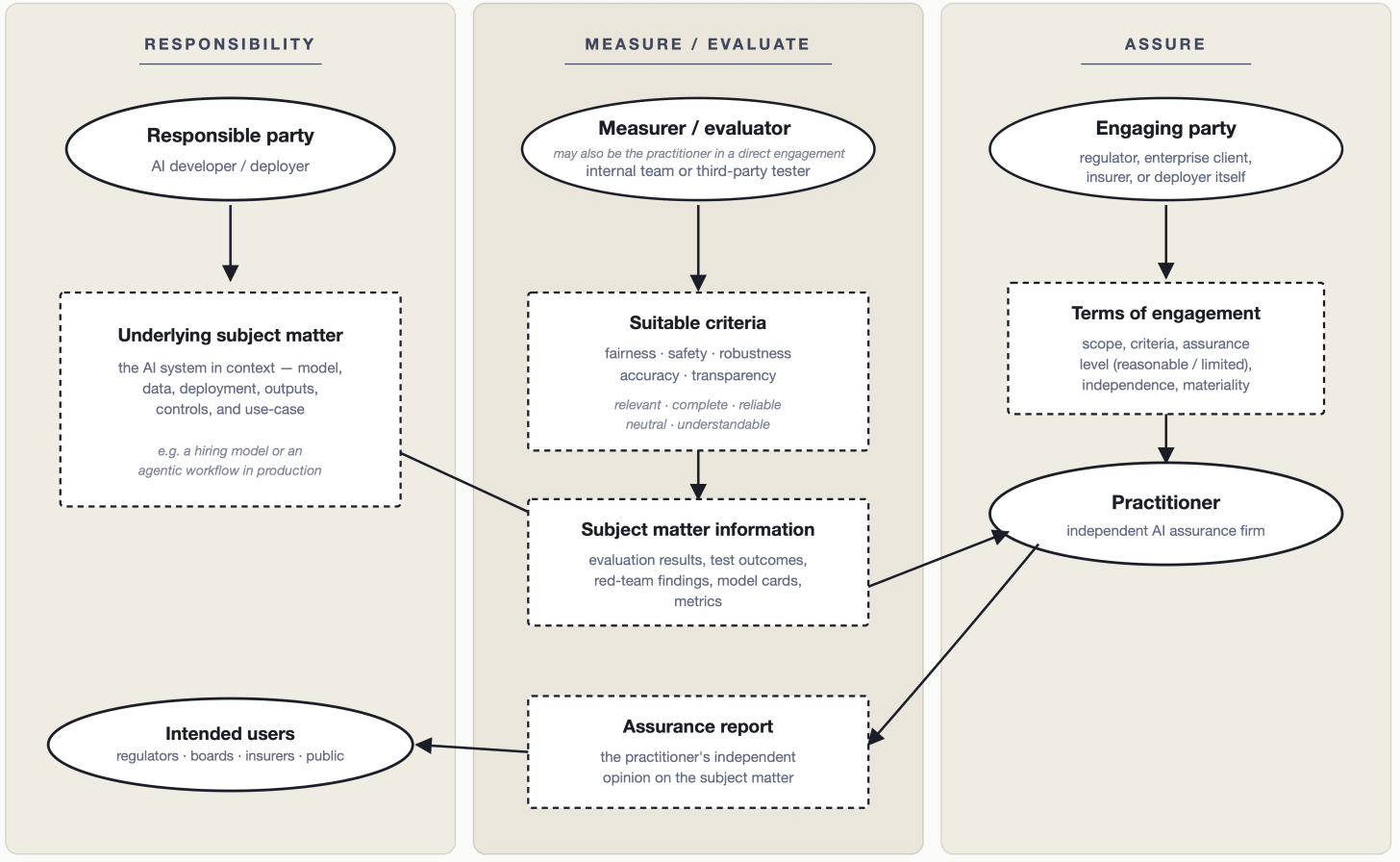
There are multiple parties with distinct roles. The standard identifies five: the responsible party (who owns the underlying subject matter), the measurer or evaluator (who measures or evaluates that subject matter against criteria, and who may be the same as the responsible party or a separate technical expert), the engaging party (who commissions the engagement and may be a regulator, the responsible party itself, or a third party), the practitioner (who provides the independent assurance), and the intended users (who rely on the practitioner’s report). In AI auditing, these roles do not always map neatly onto a single organization. An AI developer might be the responsible party while a specialized technical firm serves as the measurer or evaluator, and a regulator or enterprise client serves as both engaging party and intended user. Getting these distinctions right matters for how audit mandates are written and how the field structures itself.
There is a subject matter. In a financial audit, the subject matter is the financial position of a company. In an AI assurance engagement, the subject matter might be a hiring algorithm’s decision outputs, a risk scoring model’s behavior across demographic groups, or a generative system’s adherence to a defined content policy. It may also be process-related, such as whether and to what extent an orginization as conducted a risk assessment or follows a quality management system. The subject matter is what is being examined.
There are applicable criteria. Claims need to be evaluated against something. ISAE 3000 requires that the criteria used be suitable, meaning they are relevant, complete, reliable, neutral, and understandable. This matters enormously for AI auditing because it forces specificity. “The system is fair” is not a claim that can be audited. “The system produces demographically balanced selection rates within a defined tolerance, as measured against the criteria specified in [standard X]” can be.
The standard draws a further distinction that is practically important here: criteria can be established (issued by recognized bodies and presumed suitable) or specifically developed for the particular engagement. In financial and sustainability contexts, established criteria like IFRS or GRI are mature and widely accepted.
In AI auditing today, most criteria are still in the specifically developed category, which means the practitioner carries more burden in assessing whether the criteria are, in fact, suitable. This is one of the real areas of methodological development that the field needs to address.
There is a practitioner issuing a conclusion. ISAE 3000 engagements are conducted by professional practitioners who are required to be independent of the responsible party, competent to perform the engagement, and bound by ethical requirements, including an attitude of professional skepticism throughout. The standard also sits within a broader professional ecosystem: firm-level quality management requirements under ISQM 1 govern how assurance firms operate, and professional ethical standards govern individual practitioners. This is not a self-assessment or a vendor questionnaire. It is an independent professional, operating within a regulated professional infrastructure (ideally), forming an opinion based on sufficient appropriate evidence.
The standard also distinguishes between two levels of assurance (reasonable and limited) and two engagement structures (attestation and direct), which combine to give four possible engagement types. Reasonable assurance produces a positive-form conclusion conveying the practitioner’s opinion; limited assurance produces a negative-form conclusion conveying whether anything has come to the practitioner’s attention to suggest the subject matter information is materially misstated. Both attestation engagements (where another party measures and evaluates the subject matter and the practitioner assures the result) and direct engagements (where the practitioner performs the measurement and evaluation themselves) are available depending on the circumstances. These distinctions matter at the implementation level, but the more important point for the field right now is simply that the infrastructure for making them already exists and does not need to be reinvented.
It Has Already Worked: The DSA as Proof of Concept
This is not a theoretical argument. We have already seen ISAE 3000 applied to algorithmic accountability at regulatory scale, and the experience is instructive.
The European Union’s Digital Services Act requires independent audits of very large online platforms covering, among other things, algorithmic systems used for content recommendation and moderation. When the European Commission developed the audit methodology for those requirements, it explicitly benchmarked to ISAE 3000. It specified reasonable assurance as the required level, and referenced ISQM 1 for firm-level quality management. The regulatory design, in other words, reached for the existing professional assurance infrastructure rather than constructing something new.
BABL AI was part of the advocacy effort that helped push the Commission in that direction, and I think the outcome vindicates the approach. The framework held, the engagement structure was coherent, and the reporting requirements were intelligible to practitioners.
What the DSA experience also revealed, however, is where the genuine difficulty lies. Most of the DSA audit requirements were procedural in nature: did the platform have a risk management process, did it document its systems adequately, did it follow its stated policies. These are not trivial questions, but they are familiar territory for assurance practitioners. The Big Four firms that participated in early DSA engagements were capable of handling the procedural layer. Where the field struggled, and where there was broad acknowledgment of unreadiness, was at the technical level. The applicable criteria for assessing the actual behavior of algorithmic systems, as opposed to the processes around them, were largely absent. What existed had to be constructed from the law itself, plus bespoke sufficiency criteria developed internally by each engaging firm. That is not a failure of the assurance framework. It is a failure of criteria development. The container was ready; the contents were not.
This is the lesson I want the AI assurance community to sit with. The DSA demonstrated that the assurance infrastructure is deployable for AI accountability purposes. It also demonstrated, clearly and at scale, that suitable criteria for technical AI claims are the bottleneck.
The same lesson is now arriving in US state law. In April 2026, the Virginia General Assembly enacted Chapter 426 (S 384), directing the Joint Commission on Technology and Science (JCOTS) to evaluate the feasibility of a framework for “any person or entity seeking to act as an independent verification organization that assesses artificial intelligence models or applications.”
JCOTS is required to consider, among other things, the availability of identifiable and measurable metrics for risk, the existing standards for technical and operational mitigation, the current methodologies used to evaluate the efficacy of those mitigation requirements, and the practices employed in other states.
A report is due by November 1, 2026, and similar Independent Verification Organization proposals are under discussion in several other states. The questions JCOTS has been asked to answer map almost one-for-one onto the structure ISAE 3000 already provides: who is competent to verify, against what criteria, with what evidence, and how it is reported. The legislative scoping work would benefit enormously from beginning with that existing answer rather than constructing a parallel one.
What About ISO 42001?
A reasonable counterpoint to everything above is: why not just use ISO 42001, the AI management system standard, and the certification and accreditation infrastructure that has been built around it? It is a legitimate question, and the answer is not that ISO 42001 is wrong. It is that it is answering a different question.
ISO 42001 is a management system standard. Like ISO 27001 for information security, it specifies requirements for how an organization manages AI-related risks: governance structures, policies, risk management processes, and documentation practices. Certification to ISO 42001 tells you that an organization has implemented a conforming management system. It does not tell you how the AI system itself performs against technical claims about its behavior, fairness, safety, or accuracy.
This distinction matters because the most consequential questions in AI accountability are system-level, not process-level.
An organization can have excellent AI governance documentation and still deploy a hiring model that produces biased outputs. A management system audit will not catch that. A technical assurance engagement, conducted against suitable criteria for the specific system and its specific claims, might.
The broader conformity assessment landscape, ISO, IEC, IEEE, CEN, CENELEC, is actively developing standards that will eventually address technical AI system claims. That work is important, and the field needs it. But it will take time, and even when those standards mature, there will remain a category of consequential, specific, and often novel technical claims that require flexible assurance approaches rather than fixed conformity assessments. Complex AI systems are not static artifacts. Their behavior is stochastic, context-dependent, and subject to distributional shift. Assurance approaches for them need to reflect that complexity. ISAE 3000, precisely because it is a principles-based framework rather than a checklist, is better suited to that challenge than a conformity assessment regime alone.
It is also worth noting that a number of promising efforts are emerging to build criteria and attestation schemes specifically for AI systems, and the most defensible of these are, deliberately or not, designing themselves to live inside the professional assurance paradigm: evaluation of a defined system against published criteria, an independent assessor, and a structured report that functions as the deliverable. That convergence is a feature. The more these initiatives align with the vocabulary and obligations of ISAE 3000 (suitability of criteria, independence of the practitioner, sufficient appropriate evidence, material misstatement), the more portable and credible their outputs will be across jurisdictions and use cases.
The right answer for the field is not ISO 42001 or ISAE 3000. It is both, serving different but complementary functions: management system certification for organizational governance, and professional assurance engagements for system-level technical claims.

Where the AI-Specific Gaps Are in ISAE 3000
The structural framework that ISAE 3000 provides leaves three substantive gaps when applied to AI systems.
Suitable criteria for technical AI claims. This is the central problem. The professional assurance framework provides the structure for evaluating claims against criteria, but it cannot supply the criteria themselves. Bias metrics vary by use case, community, and legal context. Safety criteria for generative systems are not yet standardized. Performance benchmarks differ across domains. Until there is a more developed body of established criteria for AI system behavior, practitioners will continue to rely on specifically developed criteria, and the burden of assessing their suitability will fall disproportionately on individual engagements.
Applying assurance concepts to stochastic systems. The assurance framework was developed for subject matters that, while complex, are generally deterministic. Financial statements say what they say. An AI system’s outputs vary by run, by input distribution, by deployment context. Concepts like sufficient appropriate evidence, materiality, and measurement uncertainty need interpretive guidance for this setting. How many inferences constitute a sufficient sample? How should the practitioner treat variance in outputs across demographic groups when that variance itself is the subject matter? How does the inherent uncertainty of probabilistic systems interact with the notion of material misstatement? These are not unanswerable questions, but they do not yet have settled answers, and the field needs to develop them.
Practitioner competency in the technical domain. The assurance skills required by ISAE 3000, planning, evidence gathering, evaluation, professional skepticism, reporting, are well-understood and teachable. What is not yet well-understood is how to combine those skills with the technical expertise needed to evaluate AI systems at the level of their actual behavior. This is partly a curriculum problem and partly a structural one: the firms and practitioners best positioned to perform technical AI assurance are often not the ones with deep assurance training, and vice versa. The field needs to develop integrated competency frameworks that treat both as necessary rather than treating one as a substitute for the other. Early professionalization efforts are underway; the International Association of Algorithmic Auditors (IAAA), for example, is developing a code of conduct and training recognition pathway specifically for algorithmic auditors, and they deserve support from both the assurance profession and the AI community. BABL was an early mover in this space with our AI & Algorithm Auditor Certification, but the field continues to grow (e.g., AAIA by ISACA and AIGP by the IAPP) as the need for trained professionals becomes clear.
None of this requires abandoning ISAE 3000. It requires extending it thoughtfully. The professional auditing world has done this before; environmental auditing, cybersecurity assurance, and sustainability reporting all required similar methodological development before they reached their current state. The path is recognizable, even if the terrain is harder.
What the AI Assurance Field Should Be Working On
A useful distinction is between two kinds of new work. The first kind is rebuilding the infrastructure of assurance from scratch: independence requirements, report structure, firm-level quality management, evidence requirements, opinion tiering, etc. These are all addressed, in detail, by the existing assurance ecosystem, and relitigating them without reference to what already exists wastes time and risks producing weaker frameworks than what we already have. The second kind is developing the criteria and the technical methods that the existing assurance infrastructure can be applied to. That work is essential. It is also where most of the productive activity in the field is now concentrated, and it deserves more support, not less.
The productive work, then, is specific.
First, developing suitable criteria. This is the highest-leverage area. Criteria that meet the ISAE 3000 suitability requirements (relevant, complete, reliable, neutral, understandable) for the technical claims that matter most: system fairness, safety, robustness, accuracy, and transparency. This means investing in technical standards work, in empirical research on measurement validity, and in the legal and regulatory analysis needed to translate statutory requirements into auditable criteria. The DSA experience shows that the demand for this work is real and immediate. The supply is not there yet.
Second, developing interpretive guidance for applying assurance concepts to AI-specific conditions. This includes guidance on how measurement uncertainty affects materiality determinations, clarity on sampling approaches for stochastic systems, and specifications on how the measurer or evaluator role should be structured when deep technical expertise is required to generate valid subject matter information. Guidance is also needed on what “sufficient appropriate” evidence looks like when the subject matter is a probabilistic model rather than a financial statement. This is the technical standards work that will make ISAE 3000 fully operational for AI, and it is work that requires collaboration between the assurance profession and the AI research and engineering community.
Third, developing integrated practitioner competencies. Not reinventing assurance skills, which are well-established, but building the technical AI evaluation competencies that need to sit alongside them and defining how the two bodies of skill relate in practice. This includes competency frameworks for new credentialing, curriculum development for practitioners entering the field, and guidance on how firms should structure multidisciplinary engagement teams.
Encouragingly, much of this work is already underway, and the field benefits from naming it explicitly. In September 2025 the UK’s Department for Science, Innovation and Technology published its Trusted Third-Party AI Assurance Roadmap, committing £11 million through an AI Assurance Innovation Fund and convening a stakeholder consortium tasked with laying the foundations for a future AI assurance profession, including a code of ethics and a skills framework. The Ada Lovelace Institute’s July 2025 work on professionalising AI assurance has argued that AI requires “independent evaluation, audit and assurance supported by a mature, professional field that is plural rather than in the hands of a few consultancies,” which is a description that maps directly onto the assurance-profession model. The Partnership on AI’s Strengthening the AI Assurance Ecosystem workstream and its 2026 governance priorities have placed assurance mechanisms and accountability infrastructure at the center of responsible adoption. These efforts are different from one another in scope and emphasis, but they are pointing in compatible directions, and the unifying language available to them is the assurance vocabulary that ISAE 3000 already provides.
These are tractable problems. They are hard, but they are the right kind of hard, and the cost of treating them as open when professional assurance has already resolved much of the structural layer is real: it slows the development of accountability infrastructure that the public is increasingly asking for.
The Framework Is There
ISAE 3000 is not a perfect fit for AI assurance. No existing framework is. But it is the best available foundation, it has already been deployed in a major regulatory context, and it answers the majority of the structural questions that the field keeps relitigating.
The gaps that remain are real but specific: criteria development, interpretive guidance for AI-specific conditions, and integrated competency frameworks. Those are solvable problems, and solving them does not require starting from scratch.
The harder challenge is cultural and institutional. It requires the AI policy community to engage seriously with a professional literature that most technologists have not read, and it requires the assurance profession to engage seriously with technical AI evaluation in ways that go beyond process auditing. Neither community has fully made that move yet. But the foundation for what we need is already there. The question is whether we will build on it.
Shea Brown is the Founder & CEO of BABL AI, an independent AI assurance firm conducting technical audits of AI systems under ISAE 3000 assurance standards. BABL AI is a founding cohort member of the US AI Safety Institute Consortium and the International Association of Algorithmic Auditors, and Shea is Fellow at ForHumanity.
Max Rizzuto is a technical AI auditor on the assurance team at BABL AI, as well as a researcher at The Algorithmic Bias Lab.